IntroductionMany of you have probably heard the advances that a machine learning algorithm, AlphaGo, has achieved in beating the top player of Go in the game. Basically, researchers designed an algorithm consisting of a neural network that was able to play the game Go better than the top Go player in the entire world, and is considered a massive feat in machine learning. Now researchers have done the same thing in Chess using a program known as AlphaZero. As a chess enthusiast myself, I was particularly interested in how the algorithm worked, since on first hearing about the accomplishment, I was appalled. To put this into perspective, researchers designed a deep neural network consisting of an general reinforcement learning algorithm. This means that the computer was only fed the rules of the game of Chess before training, with no other knowledge of opening theory, endgame techniques, etc. And with little modification, this algorithm was extended to Shogi and Go, beating the top engines in both games, including AlphaGo. With regards to Chess, AlphaZero beat Chess Engine Stockfish in a 100 game match 28 - 72 - 0, meaning it won 28, drew 72, and lost 0 chess games against Stockfish, a chess engine known to have already beaten the top chess players. 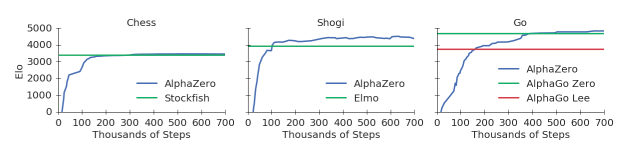 Additionally, while Stockfish took years to perfect, incorporating opening theory, endgame techniques, and quantifying small differences in positions, AlphaZero only trained for four hours before destroying Stockfish. In fact, AlphaZero need only calculate 80,000 board positions per second as compared to Stockfish's 7 million positions per second. If you wish to check out some of the games or read about the algorithm, read this paper (currently in development) by the Google DeepMind Team. Additionally, you can check out numerous articles on Chess.com or look at the Youtube channel ChessNetwork (my personal favorite) for an analysis on some of the games. I will leave a video of one analysis below. The AlgorithmOkay, so now that the introduction is out of the way, let us actually dive into the algorithm. My sources come mainly from this paper (linked above as well) as well as this infographic on AlphaZero Go (NOT AlphaZero, but similar), which you may find useful in explaining the problem. The algorithm in general is made up of two things, a deep neural network (DNN) and Monte-Carlo Tree Search (MCTS). We will first describe the Deep Neural Network and then explain its usage in Monte-Carlo Tree Search. Deep Neural Network In this section, I am only going to describe how the network is used in the algorithm, rather than the linear algebra that goes into it. If you wish to learn a bit more about that, watch these videos by 3Blue1Brown or read this blog post. I will also probably have my own blog post on how they work sooner or later. In regards to the structure, I cannot exactly say what the neural network structure is, since the paper does not specify what it is exactly, however, the infographic linked to above specifies the structure used for the AlphaGo Zero algorithm used in a previous Deep Mind project. The paper compares the two algorithms directly, and does not specify a difference in neural network structure, therefore I will assume that the structures are similar, if not the same. For now, assume the neural network is simply a function $f$ that starts out with some arbitrary parameters $\theta$, that once trained on some training data, can emulate a reasonable function that acts similar to the training data. So in general, the Deep Neural Network that is used in this program is assigned to do one thing: take in a board state (an arbitrary chess position), $s$, and output move probabilities $p$ (the probability that this next move is 'good') as well as the expected outcome of the current move $v$ (The expected value that this move will lead to a win). So for instance, if the board state is the move d4, then the neural network would produce probabilities for d5, Nf3, etc, and would give the expected outcome of the move d4, which will be some number between -1 and 1. (-1 signifying a loss and 1 signifying a win) So normally, after designing such an algorithm, one would expect to give it some data in order to optimize the parameters used in the neural net. However, since this is a general reinforcement learning algorithm, the neural net cannot be given any outside data except for the rules of the game. So, how does the network get its data? Through self play and Monte-Carlo Tree Search. Monte-Carlo Tree SearchMonte-Carlo Tree search is an algorithm that basically helps hone in on what moves are better than others in regards to the chess world. The algorithm starts with a tree with a single node representing the board state $s$, which for our purposes means that the algorithm starts with the opening position in Chess. Each node in this tree is representative of a board states, with states being connected by edges only if you can move from one state to the other. Additionally each node has four values that go with it, $N$, $W$, $Q$ and $P$, where $N$ is the number of times the node is visited (originally set to 0), $W$ is the total value of that node (originally set to 0), $Q$ is the average value of the node (set to $W/ N$) and P is the probability assigned to the node by the Deep Neural Network (set to 1 since its the opening position). Starting from the single node, the current board state is fed into the Neural Network which outputs two things, the probability of moving to the next stage ($p$) and the value of the current state, $v$. Once this is done, it creates a new layer of nodes (in this case nodes corresponding to all possible opening moves such as e4, d4, c4, etc..). When initializing these nodes, we set the probability $P$ equal to the probability assigned by the neural network. However, this is just the first step, in the second and general steps there are some more complexities. 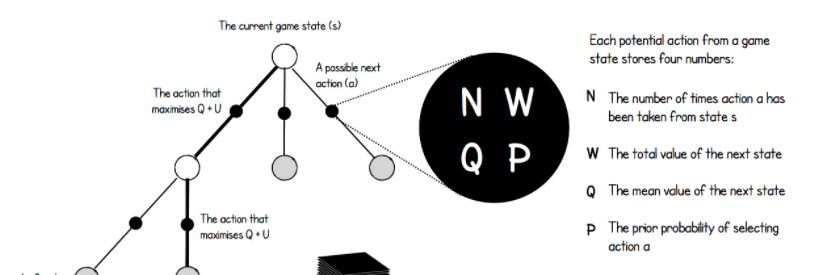 The second step (or any general step) repeats the computation, except it starts at the current board state (in this case the starting position) and proceeds down the tree until it reaches a leaf node by maximizing $Q + U(N, P)$ where $U$ is some function (not specified in the paper/infographic) involving $N$ and $P$. I will get back to the reason behind this decision later. Once it has gotten to the the leaf node, it feeds the board state $s$ it is currently at into the neural net, which outputs probabilities for another layer of nodes as well as a value $v$. Once again a new layer of nodes is created corresponding to the board states of all possible moves after the current move. This time, however, every board-state node that preceded $s$ has its $N$, $Q$ and $W$ updated as follows: $N = N + 1$, $W = W + v$ and $Q = W / N$. These steps are repeated some arbitrary number of times (for AlphaZero Go it was 1600). Then once this has happened, the tree is very expansive and filled with a lot of data. AlphaZero at this point chooses a move based on the probabilities $\pi$ corresponding to the $N$ values of each move that comes after the original state. So lets say the state was at the starting position, and lets say the only moves that had $N > 0$ were a4, e4, and d4 with $N_{\text{a4}} = 300$, $N_{\text{e4}} = 600$, and $N_{\text{d4}} = 100$. In this case $\pi$ would be $(0.3, 0.6, 0.1)$ and I would choose a4 with a 30% probability, e4 with a 60% probability and d4 with a 10% probability. This is regardless of whatever else is in the tree. The point is that after a move is chosen, the tree is not discarded, rather the root of the tree now moves down and becomes whatever board state is chosen. Additionally after the move is chosen, the board state of the game is recorded along with the probability vector $\pi$. This represents one data point, and will be used to train the DNN later. Now, after the move is chosen, the same cycle of 1600 simulations is repeated again, generating more and more of the tree. This is basically done until the game finishes, either in checkmate or a draw (based on the rules of Chess). Once this is done, each of the board state data points are updated to include the result $z$ of the game (either -1, 0 or 1). Now getting back to the earlier point of why $Q + U(N, P)$ is used as the function to decide how to move. The reason for this is that at first, $U$ dominates forcing more exploration among the nodes, so breadth is key, whereas later in the game $Q$ dominates, forcing the program to follow a more precise (not-breadth) approach. This allows both for versatility in the opening, and precision in the middle/end games. And there you have it, this is how AlphaZero plays one game against itself. If it were to play against an opponent, the only difference would be that instead of choosing the next move probabilistically, it would choose the move deterministically (always choose the move with the highest probability in $\pi$). Training the Deep Neural NetworkTo train the neural network, first the algorithm plays some number of games against itself (not specified). After doing so, it has many data-points consisting of a board state (s), a probability vector $\pi$ and an outcome $z$. It uses these values to train itself trying to minimize the loss function $(z- v)^2 + \pi^{T}log(p) + c|\theta|^2$ where the first expression is mean-squared error, the second expression is cross entropy, and the third expression is regularization (combatting overfitting). To train, the network uses batch-gradient descent, which basically means it takes a number of samples (4096 to be exact) and computes the gradient minimizing the loss function on just that data. It takes one step, throws out the data and chooses another 4096 data points from the space, and repeats some number of times. After this is all done, the network is trained and ready to go....play another set of matches against itself. This generates new data points, which are then used to retrain the neural network many times over. In order to measure its performance, the Chess ELO rating system is used, using Stockfish's actual rating as a baseline.  Comparing The Algorithm at the Beginning VS. the EndThe purpose of this section is to just compare what the algorithm looks like at the beginning of its development versus towards the end. The idea of this is to help you (the reader) and me better understand why such an algorithm was used in the first place. One of the questions I had when I first understood the algorithm was why it worked so well when at the beginning, the neural network would give such arbitrary results. Like, the probability vectors $\pi$ that are generated, are generated, ultimately, by the neural network itself with some slight adjustment. It is like feeding an untrained neural network random data and expecting it to pop up with some magical pattern. However, upon further reflection, I started to understand why there were two types of data collection. Not only were the probability vectors $\pi$ collected, but the outcome $z$ was also collected. This means at the beginning, the vectors $z$ were the main thing controlling the algorithm's development. The program was learning what lines constituted a win versus a loss. Later, towards the algorithm's matured development, the $p$'s would become more important, influencing nuanced chess play in the algorithm, since now single moves can either blunder the game or save it. Conclusion To conclude, AlphaZero is, in my opinion, one of the coolest programs ever invented on the internet. Whereas when AlphaGo beat the top Go player did not seem like such a big deal to me at the time, AlphaZero's domination against Stockfish has really shaped my view of what machine learning can do. I greatly enjoyed learning about the algorithm and writing it up for you guys to see. Thank you for reading!
1 Comment
|
AuthorMy Name is Ankit Agarwal. Check out the about me page for more information! Archives
February 2018
Categories
All
|
 RSS Feed
RSS Feed
